Crowdsourcing data is building a dataset with a large group of people contributing content. On the surface, crowdsourcing seems promising. Especially when you consider that some datasets – like the amount data you need to identify and categorize all the software, SaaS, and hardware in the world – seem so overwhelming. So, does Crowdsourcing work for IT asset data?
As it turns out, Crowdsourcing is generally considered best suited for collecting creative IDEAS (although, who can forget the “Boaty McBoatface” controversy). Crowdsourcing of DATA presents unique challenges like reliability, standardization, trustworthiness, completeness, and accuracy.
Can you imagine if Spotify crowdsourced their metadata about music? Would we have complete catalogs of work by artists or would there be gaps? Would everyone classify artists or songs in consistent genres? Would you be confident that the playlists you are sharing have accurate song descriptions?
Fortunately, Spotify relies on a trusted source for their data – Gracenote. Gracenote provides “the most comprehensive collection of worldwide music data available today” resulting in a consistent framework and experience for how you find music.
IT data, like music, requires refinement for practical use. Crowdsourcing IT asset data results in irrelevant, useless, noisy and untrusted data that cannot be used as the foundation for critical decisions. Data without context is useless, and it leads to analysis paralysis. By automatically eliminating the excess noise and chatter, Flexera makes IT data easier to consume so you can focus on maximizing value as your spend shifts from on-premises to SaaS to cloud.
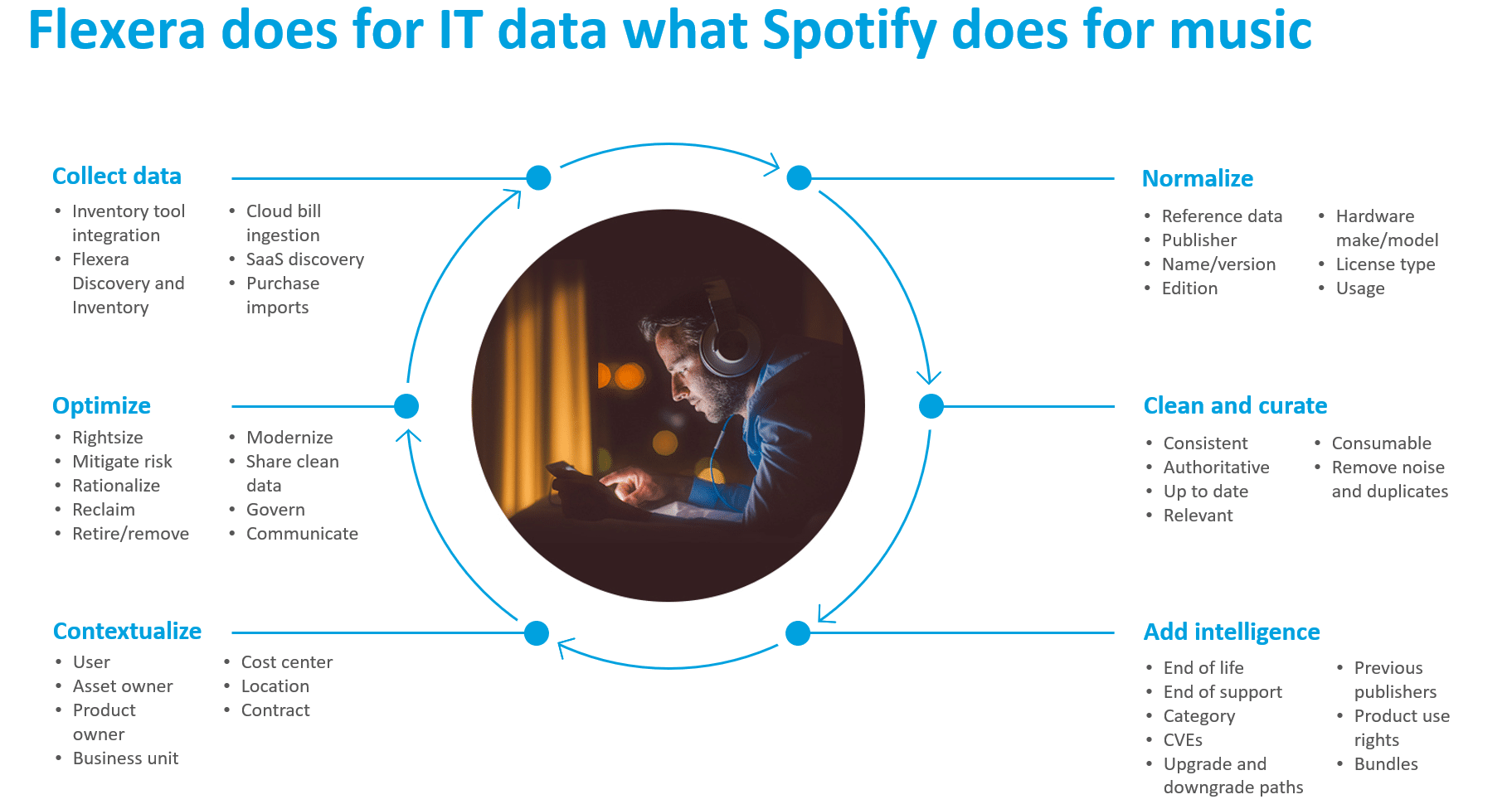
Clean data isn’t magic – it is rigor
Flexera’s visualizations of IT data may look magical, but behind that magic is an immense investment in time, discipline, standards, and research. That is where Flexera’s content team comes in – Technopedia leverages Flexera’s machine learning technology combined with the industry’s finest content team.
Flexera’s content team validates data, finds emerging patterns, and resolves anomalies and inconsistencies in IT data. Then they enrich the data with like end of life (EOL), end of support (EOS), categorization, product specifications, and vulnerabilities (CVEs).
Using Technopedia’s trusted data, organizations gain powerful insights about:
- asset lifecycles
- application currency (EOL) and risk
- extended support costs
- application rationalization opportunities
Flexera’s content team is revolutionizing the taxonomy of IT data and is the solution to the unfulfilled promise of crowdsourcing reliable data. Our content team scrubs, verifies, and standardizes critical information you need to make game changing decisions. The team systematically researches market data points like categorization, end of life, end of support, previous names, and product specifications.
Fuel the Ecosystem with trusted data
Imagine if you could share data about your IT environment as easily as you can share data about music or share your favorite playlists. All the stakeholders in your organization work with the same dataset of clean IT data to make decisions.
As the pace of change increases, 89 percent of CIOs cite the lack of quality data as an obstacle to good decision making (Source: Flexera 2020 CIO Priorities Report). They also report that decisions take too long to make, there are too many decisions, and getting consensus is difficult. These are all symptoms of not having the data, insights and analysis needed to make good decisions.
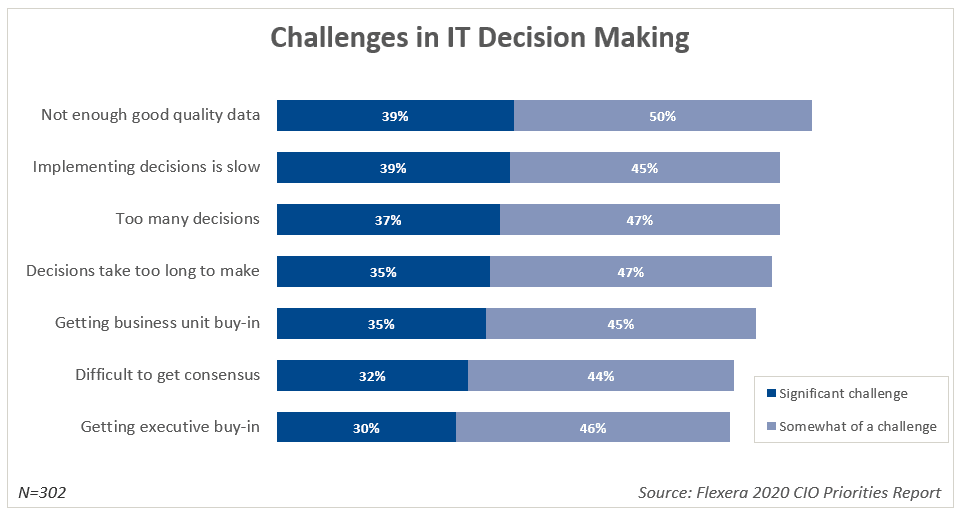
The ability to make decisions, take action, and swiftly deliver results rests on a foundation of gathering information about your complex environment by leveraging superior metadata.
With Technopedia, you can feed trusted, clean, enriched, accurate, consistent, and timely IT data into your ecosystem:
- IT Service Management/CMDB to fuel ITSM processes and reduce mean time to resolution
- IT Financial Management (ITFM) for chargeback/showback processes with actual usage data
- IT Asset Management (ITAM) for reconciliation processes with normalized data
- Enterprise Architecture for rationalization and asset lifecycle processes
- InfoSec for security prioritization processes
These processes are fundamental and the decisions are consequential. Your decisions need to be driven by information you are confident in – not data that is crowdsourced and unverified.
Most importantly, Flexera feeds these systems with the same data. This means you no longer have overlapping yet inconsistent data about the software, SaaS, and cloud investments that run your business.
Realizing the promise with Talent and Expertise
Leveraging the power, expertise, and rigor of Flexera’s data enables you to make decisions with confidence built on a foundation of trusted, relevant, and timely data.
Gartner estimates that most CMDBs fail to deliver their expected ROI due to inaccurate, irrelevant, and dirty data. Crowdsourcing of IT asset data is the unfulfilled promise that clearly hasn’t worked. Don’t crowdsource data – outsource to a massive catalog of IT data. Flexera’s passion for curation and research enables you to deliver true business outcomes and integrate quality IT asset data across your ecosystem.
Leave the dirty work of data cleansing and curation to Flexera so you can focus on the insights and analysis of the data. Flexera fulfills the promise of superior IT data so you don’t have to depend on a crowdsourcing stranger.
The end result is a consistent framework and experience for how you discover and share data, insights, and analysis of your IT estate from on-premises to SaaS to cloud.
Source : https://www.flexera.com/blog/it-asset-management/crowdsourcing-it-data/